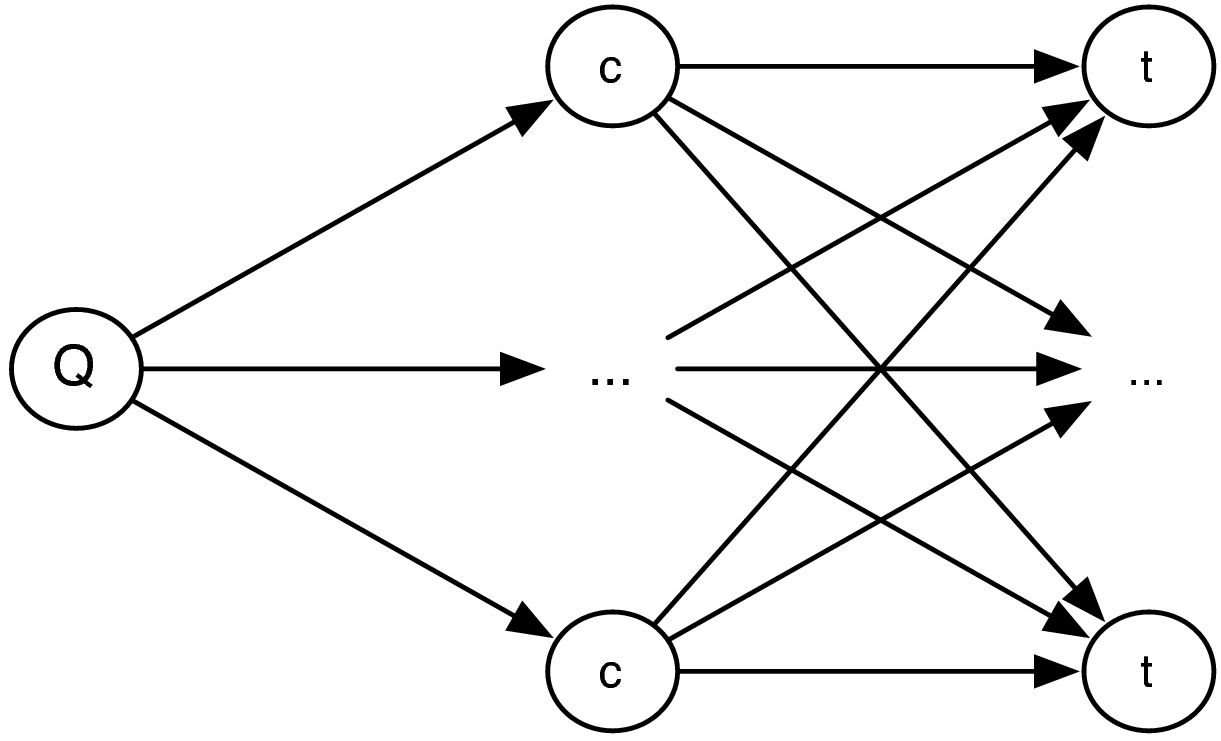
Figure 5.1: Dependence network for our conceptual language models.
| Up | Next | Tail |
Our goal is to utilize the knowledge captured using concepts from a concept language to enhance the estimation of the query model . To this end, we use the concepts as a pivot language in a double translation [169], similar to the method proposed by Berger and Lafferty [31] that was discussed in Section 2.3.1. The approach presented by French et al. [104] is also related to ours. They propose a heuristic method of associating terms with concepts. Our approach, however, utilizes the concepts that are associated with a query to find terms related to these concepts in order to estimate the expanded part of the query model, (cf. Eq. 2.10). Figure 5.1 shows a graphical representation of the dependencies of this process.
In words, first we translate the query into a set of relevant concepts, . Next, the vocabulary terms associated with the concepts are considered as possible terms to include in the query model and we marginalize out the concepts. More formally, we determine
where we assume that the probability of selecting a term is only dependent on the concept once we have selected that concept for the query.
Two components need to be estimated: , to which we refer as a generative concept model, and , to which we refer as a conceptual query model. As to the former, we will need to associate terms with concepts in the concept language. While the concepts may be directly usable for retrieving documents [128, 302, 318], we associate each concept with a weighted set of most characteristic terms using a multinomial unigram model. To this end we consider the documents that are annotated with concept as bridges between the concept and terms, by representing concepts as multinomial distributions over terms, . Generative concept models will be detailed further in Section 5.1.2 below.
The second component—the conceptual query model —is a distribution over concepts specific to the query. In some settings, concepts are provided with a query or as part of a query, see, e.g., the PubMed search interface [132], some early Text Retrieval Conference (TREC) adhoc tracks (6, 7, and 8 in particular), and the Initiative for the Evaluation of XML Retrieval (INEX) Entity Ranking track, where Wikipedia categories are used [87]. If this is not the case, however, we may leverage the document annotations to approximate this step: this is what we do in the next section.
We now turn to defining , the conceptual query model. Contrary to the alternatives mentioned at the end of the previous section, in a typical IR setting concepts are not provided with a query and need to be inferred, estimated, or recognized [339, 358]. In this chapter, we formulate the estimation of concepts relevant to a query in a standard language modeling manner, by determining which concepts are most likely given documents relevant to the query. Alternatively, we could involve the end user and ask which documents, associated concepts, or terms are relevant. Since we do not have access to such assessments we use pseudo relevance methods. In recent work and using the same framework, different approaches of estimating a conceptual query model have been studied and it was concluded that using feedback documents is far more effective than using, e.g., string matching methods that try to recognize concepts in the query [318]. In the next chapter this finding is confirmed, albeit using a different setting and test collection.
Like Lavrenko and Croft [183], we view the process of obtaining a conceptual query model as a sampling process from a number of representative sources. The user has a notion of documents satisfying her information need, randomly selects one of these, and samples a concept from its representation. Hence, the conceptual query model is defined as follows:
Here, is a set of pseudo relevant documents returned by an initial retrieval run using the textual query; is the concept language model of the document, the estimation of which is discussed in the next section. We assume that the probability of observing a concept is independent of the query once we have selected a document given the query, i.e., . The term denotes the probability that document is chosen given , which is obtained using the retrieval scores, viz. Eq. 2.8.
We assume that pseudo relevant documents are a good source from which we can sample the conceptual query model. Indeed, manual inspection shows that they are annotated with many relevant concepts, but also that they, despite being related to the query, contain a lot of noise: some concepts occur in many documents and are not very informative. Sampling from the maximum likelihood estimate for these documents would thus result in very general conceptual query models. Therefore, to re-estimate the probability mass of the concepts in the sampling process, we use a parsimonious language model. In the next section we detail how re-estimation is performed.
Table 5.3 illustrates the difference between a maximum likelihood estimation and a parsimonious estimation. It shows the concepts (in this case MeSH terms) with the highest probability for topic 186 from the TREC Genomics 2006 test collection. The conceptual query model based on the parsimonious document models contains more specific—and thus more useful—concepts, such as PRESENILIN-1 and PRESENILIN-2. The model based on maximum likelihood estimates includes more general concepts such as HUMANS, which are relevant but too general to be useful for searching.
|
|
Given Eq. 5.1, our goal is to arrive at a probability distribution over vocabulary terms for each concept in the concept language used for annotating the documents. We determine the strength of the association between a term and a concept by looking at the annotations made by the trained annotators who have labeled the documents. In the end, this method defines the parameters of a generative language model for each concept: a generative concept model. We determine , i.e., the strength of association between a concept and a term , by determining the probability of observing given . Concepts that are used to annotate documents may have different characteristics from other parts of a document, such as title and content. Annotations are selected by human indexers from a concept language while the remaining content consists of free text. Since the terms that make up the document are “generated” using a different process than the concepts, we may assume that and are independent and identical samples given a document in (or with) which they occur. So, the probability of observing both and is:
where denotes the set of documents annotated with concept . We assume each document to have a uniform prior probability of being selected and obtain:
Hence, it remains to define three terms: , , and . First, the term functions as a penalty for frequently occurring and thus relatively non-informative concepts. We estimate this term using MLE on the document collection:
where is the number of times document is labeled with concept (which is typically 1).
|
|
||||||||||||||||||||||||||||||||||||||||||||||
Next we turn to , for . The size of these models (in terms of the number of words or the number of concepts that receive a non-zero probability) may be quite large, e.g., in the case of a large document collection or in the case of frequently occurring concepts. Moreover, as exemplified above, not all of the observed events (where events are either terms or concepts) are equally informative. Some may be common, whilst others may describe the general domain of the document. Earlier in the thesis, we have noted that it is common to consider each document as a mixture of document-specific and more general terms (cf. Eq. 2.5); we now generalize this statement to also include concepts. Further, given this assumption, we may update each document model by reducing the amount and probability mass of non-specific events. We do so by iteratively adjusting the individual probabilities in each document, based on a comparison with a large reference corpus such as the collection. More formally, we maximize the posterior probability of after observing :
Note that may be set differently for (Eq. 2.5) and . For these estimations, we fix based on [136, 211, 215]. We then apply the following EM algorithm until the estimates do not change significantly anymore:
This updating mechanism enables more specific events, i.e., events that are not well-explained by the background model, to receive more probability mass, making the resulting document model more specific. After the EM algorithm has converged, we remove those events with a probability lower than a certain threshold . Thus, the resulting document model for terms, , to be used as in Eq. 5.4 is given by:
where is a document-specific normalization factor: . Table 5.4 provides an example of the effects of applying Eq. 5.9 on a document from the CLEF-DS document collection (that will be introduced in Section 5.2). Similarly, the resulting document model for concepts, , to be used for in Eq. 5.4, is given by:
where is a document-specific normalization factor: . Table 5.3 provides an example of the effects of applying Eq. 5.10 on a topic from the TREC document collection (that will be introduced in Section 5.2). For the experiments in this chapter we fix .
| Up | Next | Front |