Figure 2.1: Example query model for the topic “poker tournaments,” obtained
using RM-1 (See page 55). The size of a term is proportional to its probability in
the query model.
| Up | Next | Prev | PrevTail | Tail |
Examining how queries can be transformed to equivalent, potentially better queries is a theme of recurring interest to the IR community. Such transformations include expansion of short queries to long queries [242, 327, 345], paraphrasing queries using an alternative vocabulary [92], mapping unstructured queries to structured ones [224, 225], identifying key concepts in verbose queries [29], substituting terms in the query [86], etc.
Multiple types of information source have been considered as input to the query transformation process. In traditional set-ups, resources such as thesauri and controlled vocabularies have long been used to address word mismatch problems [21, 327], whilst other techniques are based on analyzing the local context of a query [345]. In relevance feedback, retrieved documents (possibly with associated relevance assessments) serve as examples to select additional query terms from [267]; relevance feedback will be further introduced in Section 2.3.2. Other types of information sources to be used for query transformations include recent ones such as using anchor texts or search engine logs for query substitutions [86, 335]. Another recent example is where users complement their traditional keyword query with additional information, such as example documents [24], tags [73], images [76, 91], categories [338], or their search history [20]. The recent interest of the semantic web community regarding models and methods related to ontologies has also sparked a renewed interest in using ontological information for query expansion [35, 268].
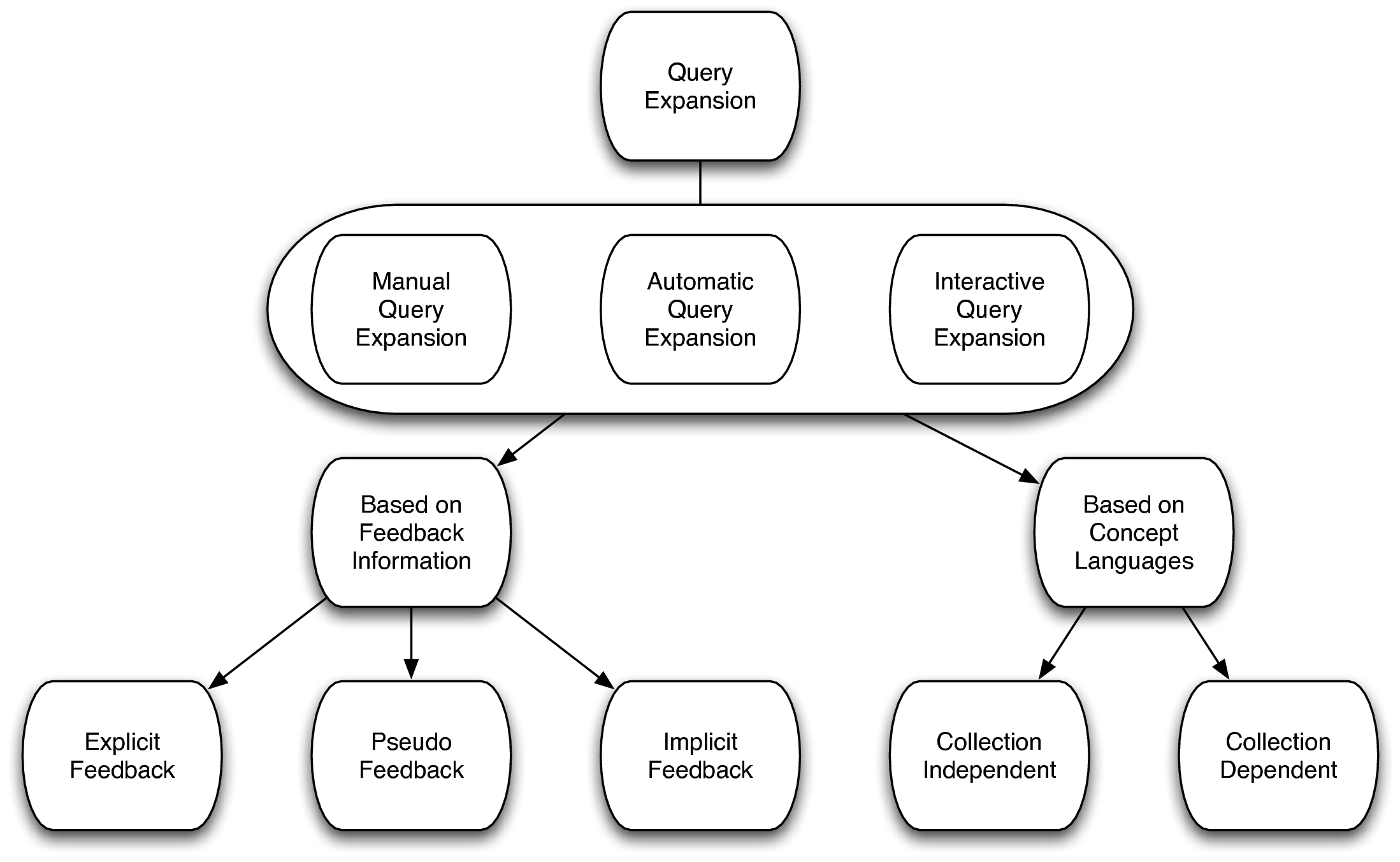
Query expansion is a form of query transformation that aims to bridge the vocabulary gap between queries and documents by adding and reweighting terms in the original query; Dang and Croft [86] show that it is more robust than substituting terms in the query. Figure 2.2 is based on a diagram from [97] and shows various types of query expansion as well as the various sources of information that are commonly used. Query expansion can be local or global [345]. Global query expansion uses global collection statistics or “external” knowledge sources such as concept languages to enhance the query. Examples of the former include word associations such as those defined by term co-occurrences or latent semantic indexing (LSI) [88, 325]. Concepts and lexical-syntactic relations as defined in a thesaurus have been used with varying degrees of effectiveness [21, 57, 97, 209, 252, 268, 321, 327]. Local query expansion methods try to take into account the context of a query, specifically through looking at a set of feedback documents. Finkelstein et al. [102] propose to use the local context of query terms as they appear in documents to locate additional query terms. One might also consider a user’s history or profile, in order to automatically enrich queries [168]. Much later, this idea was adopted in a language modeling setting by Bai and Nie [20]. One could utilize many different sources of information to improve the estimate of the query model, including external corpora [92], example documents [24], amongst others. Lease et al. [184] apply machine learning to learn which terms to select from verbose queries. Cao et al. [58] use an support vector machine (SVM) classifier to learn which terms improve retrieval performance. He and Ounis [124] use machine learning to select documents for relevance feedback. In the remainder of this section we discuss common approaches to query modeling, including the translation model, relevance feedback, and term dependencies. In Chapter 4 we introduce and evaluate new relevance feedback methods for query modeling. In Chapter 5 we introduce a method that uses query modeling in conjunction with document annotations for query modeling. In Chapter 6 we use a machine learning method to map queries to concepts and in Chapter 7 we use concepts obtained using machine learning for query modeling.
Berger and Lafferty [31] integrate term relationships in the language modeling framework using a translation model. They view each term in a query as a translation from each term in a document, which is modeled as a noisy channel. Here, each source term has a certain probability of being translated into another term (including a “self-translation” onto the source term) and each document is then scored based on the translated terms. More formally,
where is the translation probability of to . Berger and Lafferty [31] estimate this relation for pairs of words in the same language by considering each sentence parallel to the paragraph it contains. In essence, Eq. 2.11 describes a form of smoothing that uses translation probabilities instead of collection estimates. It also features an inherent query expansion component.
Various other authors have built upon this model. For example, Cao et al. [57] and Nie et al. [241] incorporate WordNet relations and co-occurrence information for query modeling. Jin et al. [150] estimate the probability of using a query as the title for each document, and Wei and Croft [340] smooth each document using a number of topic models obtained using LDA (which is introduced below). Lalmas et al. [176] use the translation model to leverage information from lexical entailments. Lavrenko and Croft [183] use the same intuitions to incorporate relevance feedback information, as we describe in the next section. Jimeno-Yepes et al. [149] use this model to include semantic information when ranking documents, with similar intuitions as we present in Chapter 5.
A well-studied source of information for transforming a query is the user, through relevance feedback [81, 267, 272, 276]: given a query, a set of documents, and judgments on the documents retrieved for that query, how does a system take advantage of the judgments in order to transform the original query and retrieve more documents that will be useful to the user? Despite a history dating back several decades, relevance feedback is perhaps one of the least understood techniques in IR. Indeed, as demonstrated by the recent launch of a dedicated relevance feedback track at TREC [48], we still lack the definitive answer to this question.
Relevance feedback is a form of local query expansion that relies on the analysis of feedback documents, for example obtained through an initial retrieval run. Three variants with respect to how the judgments are obtained can be discerned: pseudo, explicit, and implicit relevance feedback. Pseudo relevance feedback methods assume the top ranked documents to be relevant. It was first introduced by Croft and Harper [81] and applied in the context of the PRP model to obtain an alternative for the IDF term weighting function. Explicit relevance feedback uses explicit relevance assessments from users [9, 165, 323, 345]. Implicit relevance feedback obtains such assessments indirectly, e.g., from query or click logs [9, 85, 153], historical queries [283] or by considering user interactions with the system, such as dwell time and scrolling behavior [162]. White et al. [341] compare implicit relevance feedback (obtained from user interaction with the system) with explicit relevance feedback and find that the two methods are statistically indistinguishable.
In a language modeling setting, relevance feedback has been mainly applied to (re-)estimate query models [175, 181–183, 310], although other approaches such as document expansion using query feedback also exist [239]. In the remainder of this section, we detail the various relevance feedback methods for query modeling that we evaluate and employ in later chapters. First, we consider the simplest case where the set of relevant documents is considered as a whole. We then turn to Zhai and Lafferty’s model-based feedback (MBF) [354] and Lavrenko and Croft’s relevance model (RM) [182]. Figure 4.1 displays these four models using Bayesian networks, whereas Table 4.1 lists the abbreviations used throughout the thesis (see page 107).
If we were able to obtain a complete set of relevance judgments from the user and, hence, could fully enumerate all documents relevant to a query, we could simply use the empirical estimate of the terms in those documents to obtain . Given all sources of information available to the system (the query, assessments, and documents in the collection), the parameters of this model would fully describe the information need from the system’s point of view. The joint likelihood of observing the terms given under this model (again assuming independence between terms) is:
where denotes the set of relevant documents. Then, we can use a maximum likelihood estimate over the documents in to obtain
Below, we refer to this model as maximum likelihood expansion (MLE).
In contrast to this hypothetical case, however, a typical search engine user would only produce judgments on the relevance status of a small number of documents, if at all [299]. Even in larger-scale, system-based TREC evaluations, the number of assessments per query is still a fraction of the total number of documents in the collection [50, 52, 288]. So in any realistic scenario, the relevance of all remaining, non-judged documents is unknown and this fact jeopardizes the confidence we can put in the model described by Eq. 2.12 to accurately estimate . This is one of the motivations behind the model proposed by Zhai and Lafferty [354] that iteratively updates by comparing it to a background model of general English. We further detail their model below.
Besides having a limited number of relevance assessments, not every document in is necessarily entirely relevant to the information need. Ideally, we would like to weight documents according to their “relative” level of relevance. We could consider each relevant document as a separate piece of evidence towards the estimation of , instead of assuming full independence as in Eq. 2.13. Let’s consider the following sampling process to substantiate this intuition. We pick a relevant document according to some probability and then select a term from that document. Assuming that each term is generated independently once we pick a relevant document, the probability of randomly picking a document and then observing is
Then, the overall probability of observing all terms can be expressed as a sum of the marginals:
The key term here is ; it conveys the probability of selecting given or, slightly paraphrased, the level of relevance of . Lavrenko and Croft [182] use this mechanism to obtain a posterior estimate of , as detailed below. In Chapter 4 we introduce and evaluate a novel way of estimating both and .
Zhai and Lafferty [354] propose a model for pseudo relevance feedback that is closely related to MLE. Their model also assumes document independence (like Eq. 2.13), but they consider the set of feedback documents to be a model consisting of a mixture of two components: a model of relevance and a general background model. More formally:
One can use an estimation method such as expectation maximization (EM) [90] to maximize the likelihood of the observed data (the relevant documents):
After converging, Zhai and Lafferty use as in Eq. 2.10. Like MLE, this model also discards information pertinent to the individual relevant documents and only considers the set as a whole. The close relation between the two models is made visible by entering in Eq. 2.17, which yields and, hence, MLE (cf. Eq. 2.13):
| (2.19) |
Various other researchers have used the intuitions behind MBF for their models. For example, Tao and Zhai [310] extend MBF and remove the need for the subsequent interpolation of the initial query and (cf. Eq. 2.10), by defining a conjugate prior on . Hiemstra et al. [136] follow the same assumptions as MBF, but propose to model as a three component mixture by incorporating a separate document model, as described below.
In contrast to the estimation method used by MBF, the relevance modeling approach uses relevance feedback information to arrive at a posterior estimate of [182]. Relevance models are one of the baselines we employ at various points later in the thesis. They are centered around the notion that there exists a query-dependent model of relevance; the initial source for estimating the parameters of this model is the query itself, but relevance feedback information can provide additional evidence. It is assumed that for every information need there exists an underlying relevance model and that the query and relevant documents are random samples from this model. The query model, parametrized by , may be viewed as an approximation of this model. However, in a typical retrieval setting improving the estimation of is problematic because we have no or only limited training data. Lavrenko and Croft [182] discern three situations:
In the first and second situation, they define:
For the first situation (called RM-0), is set to 1, which makes this model equivalent to MBF except for the way it treats the set of relevant documents. MBF considers the set as a whole, whereas RM considers each document individually. So, besides using a different estimation method, MBF is highly similar to RM, except for two assumptions: MBF assumes (i) independence between relevant documents and (ii) . In situation 2, is set to a value between 0 and 1.
In situation 3, i.e., the case of pseudo relevance feedback where is a set of top-ranked documents of which the relevance status is unknown, Lavrenko and Croft discern two methods (model 1 and model 2). Contrary to situations 1 and 2, these are also dependent on the initial query. Model 2 (RM-2) is defined as:
where
Then we can rewrite Eq. 2.21 into:
As is clear from Eq. 2.23, this model considers each relevant document individually and explicitly takes the initial query into account by first gathering evidence from each document for a query term and, next, combining the evidence for all query terms. Model 1 (RM-1), on the other hand, is defined as:
This restructured equation makes clear that in case of RM-1 the evidence is first aggregated per query term and subsequently per document. So, RM-1 and RM-2 differ in the way they aggregate evidence of terms co-occuring with the query: RM-1 first aggregates evidence for all query terms and then sums over the documents, whilst RM-2 does the opposite. In both RM-1 and RM-2, is assumed to be uniform, i.e., .
Various extensions and adaptations of relevance models have been proposed in the literature. Li [188] adds three heuristics to the relevance model estimation, including adding the original query as pseudo-document, adding a document length based prior, and discounting a term’s probability based on estimates on the collection. Diaz and Metzler [92] estimate relevance models on external corpora and find that this approach helps to reduce noise in the query models; a finding corroborated by Weerkamp et al. [337]. Balog et al. [24] apply relevance model estimation methods on example documents provided by the user and find that their model significantly outperforms several baselines. In [208, 209] we have biased the relevance model estimations towards concepts assigned to the documents. This approach was later refined in [221] and will be further introduced in Chapter 5.
Hiemstra et al. [136] propose an approach to language modeling, called parsimonious relevance models (PRM), that is based on [297]. It hinges on the notion that language models should not model language blindly, but instead model the language that distinguishes a relevant document from other documents. Hiemstra et al. present an iterative algorithm based on EM that takes away probability mass from terms that are frequent in a model of general English and gives it to the terms that are distinct in a document. It re-estimates the document models as follows:
until the estimates do not change significantly anymore. The resulting is then used instead of the document model in Eq. 2.8.
In the case of relevance feedback, Hiemstra et al. [136] define a three-level model, that adds a model of relevance to Eq. 2.25. In this case, each relevant document is considered to be a linear interpolation of these three models:
Given a set of relevant documents, the following iterative algorithm is applied:
Hiemstra et al. [136] propose to use instead of the query model, again using Eq. 2.8. When a fixed value of is used in Eq. 2.27, it results in RM-0 with parsimonious document models.
Hiemstra et al. [136] find that the size of the posting list for each document (in which the terms with a non-zero value are stored for each document in an index) can be greatly reduced, without a significant loss in retrieval performance. When Eq. 2.27 is evaluated on a routing task (cf. Chapter 3), they find that retrieval performance is slightly improved over RM-0. They do not find further improvements when introducing re-estimated document models (i.e., when ).
In [216] we have proposed a combination of MBF and RM-2 that uses relevance models in conjunction with the estimation methods of MBF. In Chapter 4 we also include PRM in the comparative performance evaluations. In Chapter 5 we apply a similar EM algorithm when incorporating document level annotations during query modeling and find that this step is essential for obtaining significant improvements.
IR has a long history of attempts to incorporate syntactic information such as term dependencies, with varying success [291, 294]. All language modeling variations presented so far are based on the assumption that terms (in both queries and documents) are independent of each other. Given common knowledge about language, such an assumption might seem unrealistic (or even plainly wrong). Various researchers have attempted folding in syntactic information (ranging from n-gram information [229, 290, 301] to using HAL (Hyperspace Analog to Language) space [137]). Such efforts have not yet resulted in consistent, significant improvements however. This fact is commonly attributed to data sparsity in corpora; most of the features (e.g., the n-grams) simply do not occur with sufficient frequency.
Song and Croft [290] do observe an improved performance for their proposed general language model that combines bigram language models with Good-Turing estimates and corpus-based smoothing of unigram probabilities. This form of smoothing interpolates the probabilities for bigrams with those of unigrams; the probability of observing the sequence of terms becomes:
where
Such back-off bigram language models give a higher probability to documents containing a bigram from the query as a phrase (e.g. documents containing the phrase “information retrieval” would obtain a larger probability than documents containing solely the constituent terms). Srikanth and Srihari [301] build upon this idea and propose the use of so-called biterms. Biterms are similar in nature to back-off bigram language models, with the distinction that the constraint of term ordering is relaxed. Using their method, a document containing the phrase “retrieval of information” would be assigned the same probability as using the bigram model. Similar intuitions have been applied to query modeling and applying positional information there has met with improvements in retrieval performance, especially in terms of precision on larger web collections [224, 232].
| Up | Next | Prev | PrevTail | Front |